Hosting-infrastructuur bouwen anno 2024: real-time tasks (deel 2)
Hosting-infrastructuur bouwen anno 2024: real-time tasks (deel 2)
Op een hosting-platform gebeuren constant dingen real-time: certificaten aanvragen, back-ups herstellen, nodes upgraden... noem maar op.
We hebben een takensysteem gebouwd waarmee API-users tasks kunnen starten, volgen en retryen - op basis van Celery en FastAPI.
Dit project laat ons Python-hart sneller kloppen, en we zijn erg trots op het resultaat. Laten we erin duiken.
Waar we nu staan
Voordat we kijken hoe ons takensysteem technisch werkt, laten we eerst even kijken wat het doet.
Neem het voorbeeld van een certificaat aanvragen:
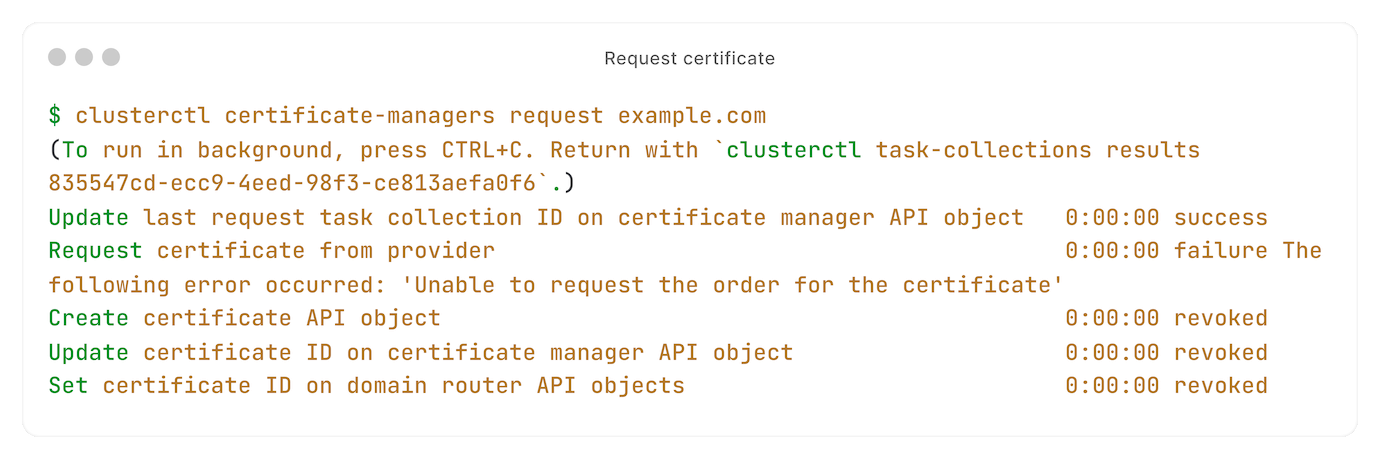
De tasks worden op de achtergrond uitgevoerd, buiten de HTTP request-response cycle.
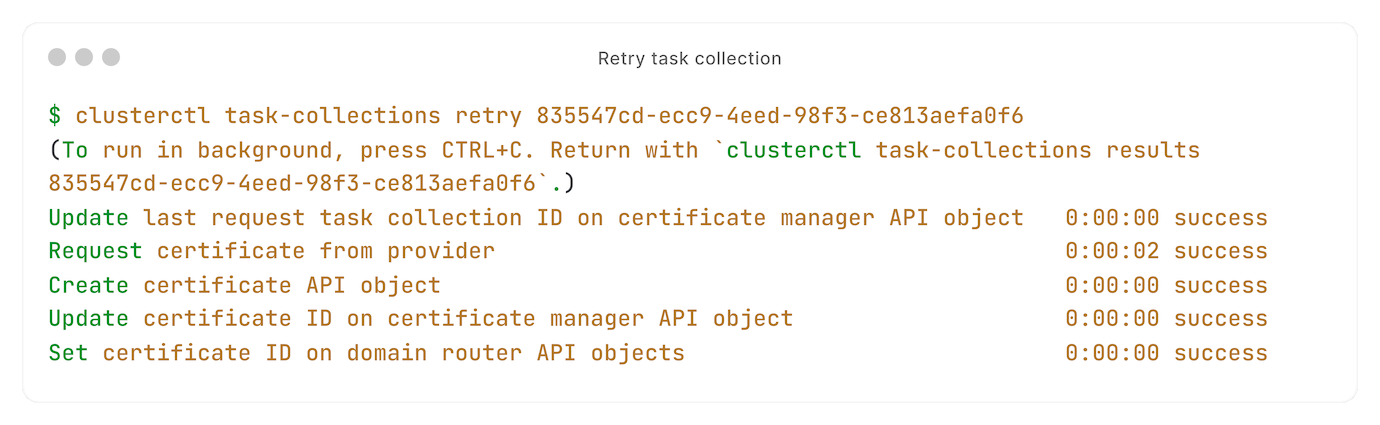
Eén van onze tasks mislukte. Geen probleem, daarom hebben we retries:
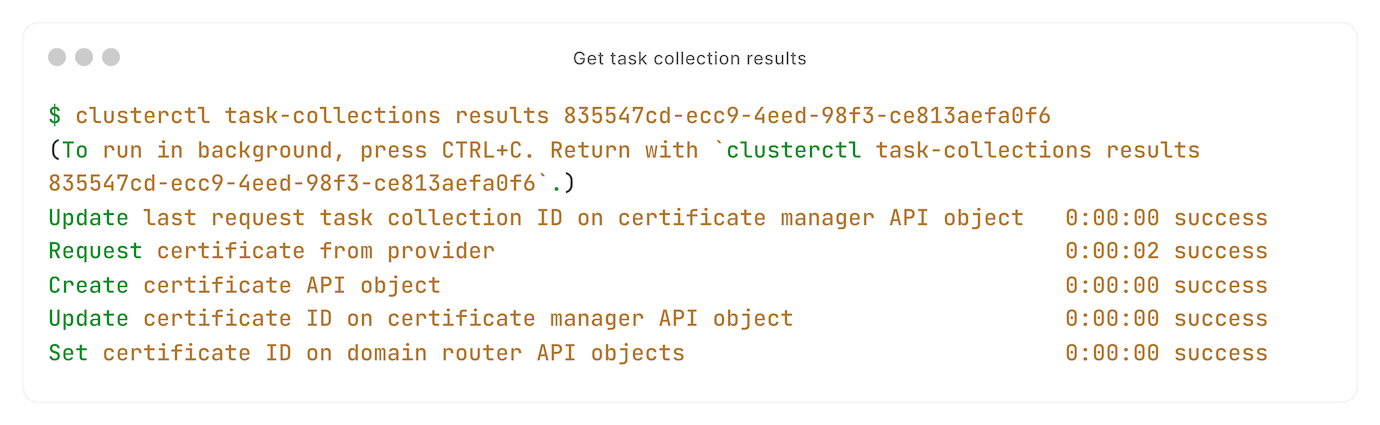
Wil je tasks achteraf bekijken? Het kost maar één commando:
We hebben geen bestaande oplossingn gebruikt, zoals django-celery of Laravel queues.
Dus hoe werkt het? Laten we onder de motorkap kijken.
Een haat-liefdeverhouding met Celery
Om tasks uit te voeren, gebruiken we Celery. Een discutabel maar veelvoorkomende keuze.
We zijn op de hoogte van alternatieven zoals Prefect en Dramatiq - ze hebben geleerd van wat Celery niet zo goed doet.
Maar simpel feit is: niets verslaat de stabiliteit van Celery. Het is een volwassen project, met een stabiele API - in een professionele omgeving heel veel waard.
Met Celery in onze toolbox, gaan we naar het interessante gedeelte: tasks starten en volgen met onze FastAPI API.
Tasks uitvoeren met Celery
Alle tasks moeten één voor één worden uitgevoerd, in een specifieke volgorde. We kunnen geen certificaat aanmaken als we die niet eerst kunnen aanvragen. We kunnen een back-up niet herstellen als we die niet eerst kunnen downloaden. Je snapt het idee.
Celery heeft een ingebouwde oplossing: chains.
Een simpel voorbeeld:

In dit voorbeeld kopen we een tafel, en maken die dan schoon.
We kunnen geen tafel schoonmaken die we niet hebben. De opschoon-task wordt dus nooit bereikt als de koop-task mislukt.
Voordat we verder gingen met het volgende deel, moesten we rekening houden met twee eigenaardigheden.
Nummer één: nadat een chain is gecalled, kunnen we Celery niet zomaar vragen: "welke tasks horen bij deze chain?". Het kan wel, maar alleen door te vertrouwen op half verborgen implementation details.
Als stabiele oplossing, slaan we de tasks in iedere chain zelf op. Eerst 'freezen' we de signature om een UUID te pre-allocaten, die we opslaan:
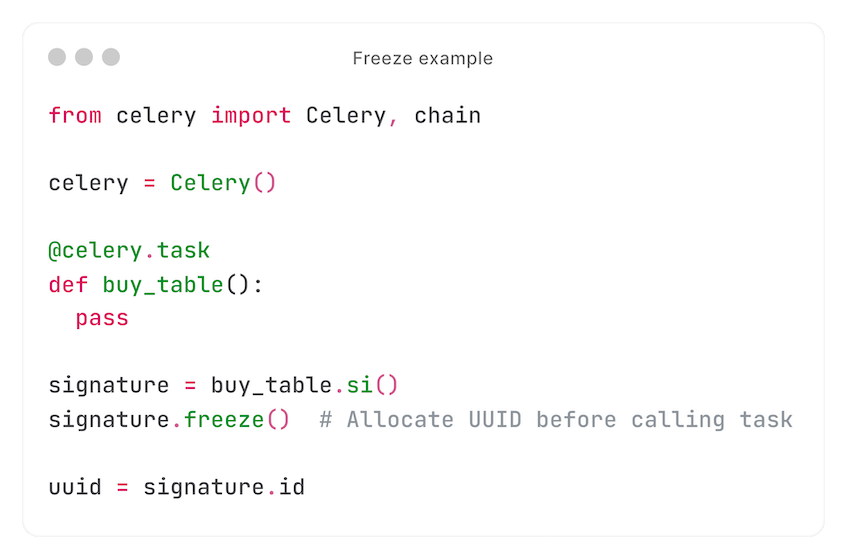
De tweede bijzonderheid: chains kunnen maar één task hebben. Het komt zelden voor, maar kan gebeuren. In dat geval voegen we een 'dummy'-task toe om Celery dit als een chain te laten beschouwen.
In dit specifieke geval geven we de voorkeur aan deze aanpak; logica onderhouden en testen voor zelden gebruikte code is meestal een anti-pattern.

Retries in een wisselvallige wereld
In navolging van het eerdere voorbeeld: stel dat we een externe API-call doen om de tafel te kopen. Wat als die API onbereikbaar is?
Onze task zal falen. En op een gegeven moment willen we het opnieuw proberen.
Misschien is het niet evident, maar dit is verreweg het meest complexe onderdeel. Om te begrijpen waarom, moet je één ding weten: Celery ondersteunt retries van tasks, maar niet buiten een task.
Zo kunnen we dit doen:

... maar dit niet:

Er zijn workarounds om een task op te halen nadat deze is uitgevoerd. Maar zelfs die lossen ons probleem niet volledig op: alleen die task zou opnieuw worden geprobeerd, niet tasks in de chain die erna komen.
We hebben een creatieve oplossing bedacht.
Wanneer een gebruiker een task collection retried, retryen we niet daadwerkelijk mislukte tasks. In plaats daarvan maken we een nieuwe chain, met tasks die identiek zijn aan de niet-succesvolle tasks - inclusief de UUID, zodat onze database 'automagisch' naar de nieuwe tasks verwijst.
Dit vergt wat ingenieus denkwerk.
Ten eerste slaan we, wanneer we de oorspronkelijke chain maken, alles op wat we moeten weten over die tasks. Sommige informatie is afkomstig van 'extended results' (kwargs, args, naam, etc.), overige informatie wordt opgeslagen in onze database (signature immutability, etc.)

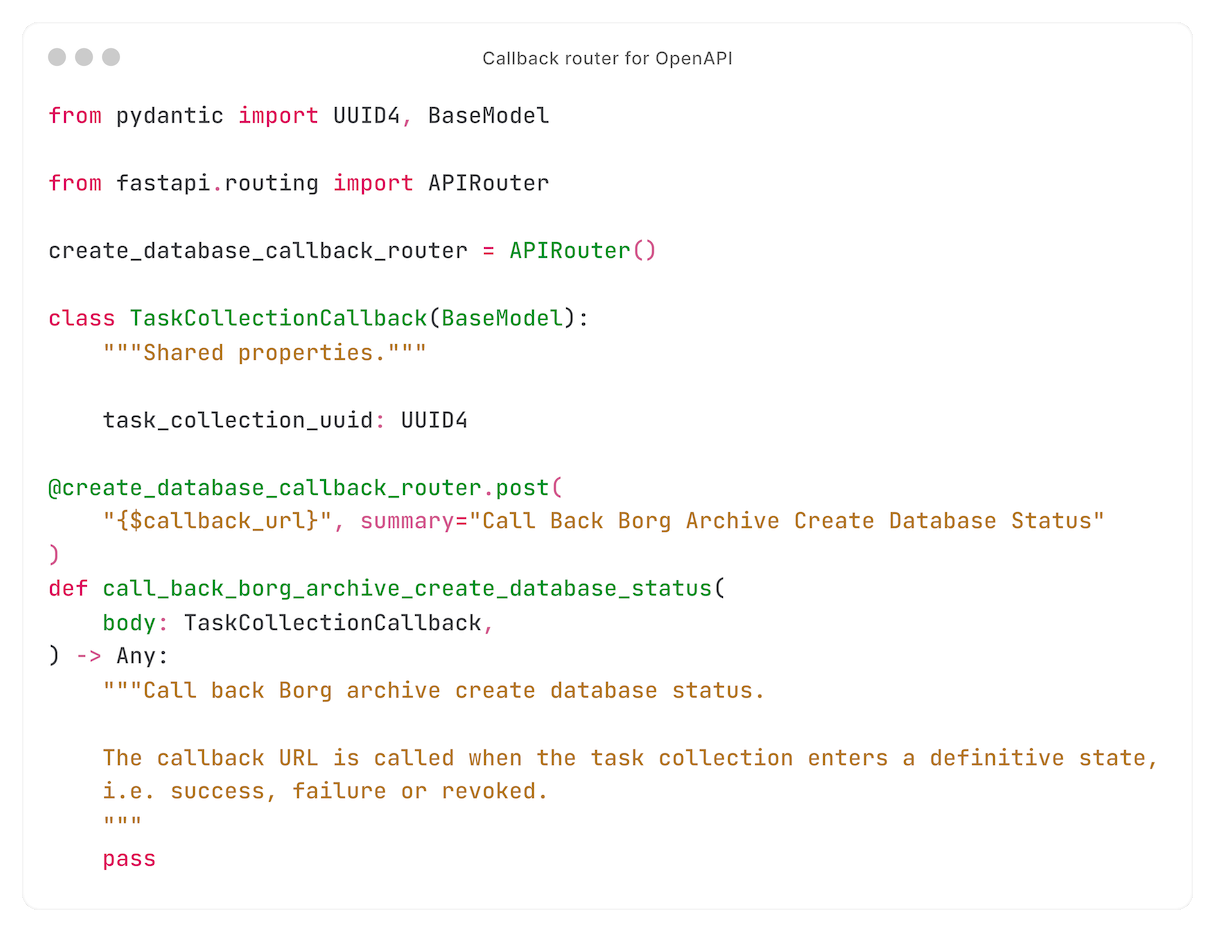
Callbacks for automation
Many users integrate the Core API with their own systems. For example, they may send notifications when a certificate request fails.
For that, we have callbacks.
Multiple API endpoints return a task collection. Every such endpoint accepts a callback URL.
When the callback URL is specified, a task is added to the chain - calling that URL. Using Celery's `on_error` function, that task is always executed - even when a task in the chain fails.

The result
Een complexe backend kan op een zeer gebruiksvriendelijke manier worden gepresenteerd. Dit project is daar een uitstekend voorbeeld van.
Dit project laat ook zien dat het goed kan zijn om het wiel deels opnieuw uit te vinden, zolang je niet het hele wiel opnieuw uitvindt. Met de stabiele basis van Celery konden we de API-implementatie precies zo bouwen zoals we dat willen, zij het met veel onderzoek en het omzeilen van sommige eigenaardigheden.
Op het moment dat we dit schrijven, is dit ons verlanglijstje:
- Meldingen ontvangen van specifieke gefaalde tasks: sommige real-time tasks kunnen getriggered worden door gebruikers, terwijl problemen alleen door ons opgelost kunnen worden. Nu moeten gebruikers ons vragen te kijken naar zo'n probleem, wat niet efficiënt is. (Daarvoor zouden we `on_error` kunnen gebruiken.)
- Celery-workers kunnen stukgaan wanneer Redis tijdelijk onbereikbaar is. Dit bekende probleem wordt onderzocht door de community (waaronder wijzelf).
Al met al zijn we erg trots op het eindresultaat: een helder, gebruiksvriendelijk en robuust takensysteem.
Vind jij dit soort projecten net zo spannend? Bekijk onze vacatures.
Volgende keer: tasks met RPC
In het volgende deel, gaan we in op real-time tasks uitvoeren - zoals back-ups terugzetten - met RPC.