Hosting-infrastructuur bouwen anno 2024: RPC-acties (deel 3)
Hosting-infrastructuur bouwen anno 2024: RPC-acties (deel 3)
Een CMS installeren. Een FPM pool herstarten. Een back-up herstellen.
Deze acties hebben twee dingen gemeen: ze worden real-time uitgevoerd, en er moeten dingen voor op cluster-nodes worden uitgevoerd.
Hoe? RPC via RabbitMQ (AMQP). Laten we kijken.
Laten we een willekeurige real-time actie pakken: de login-URL van een WordPress-website ophalen:
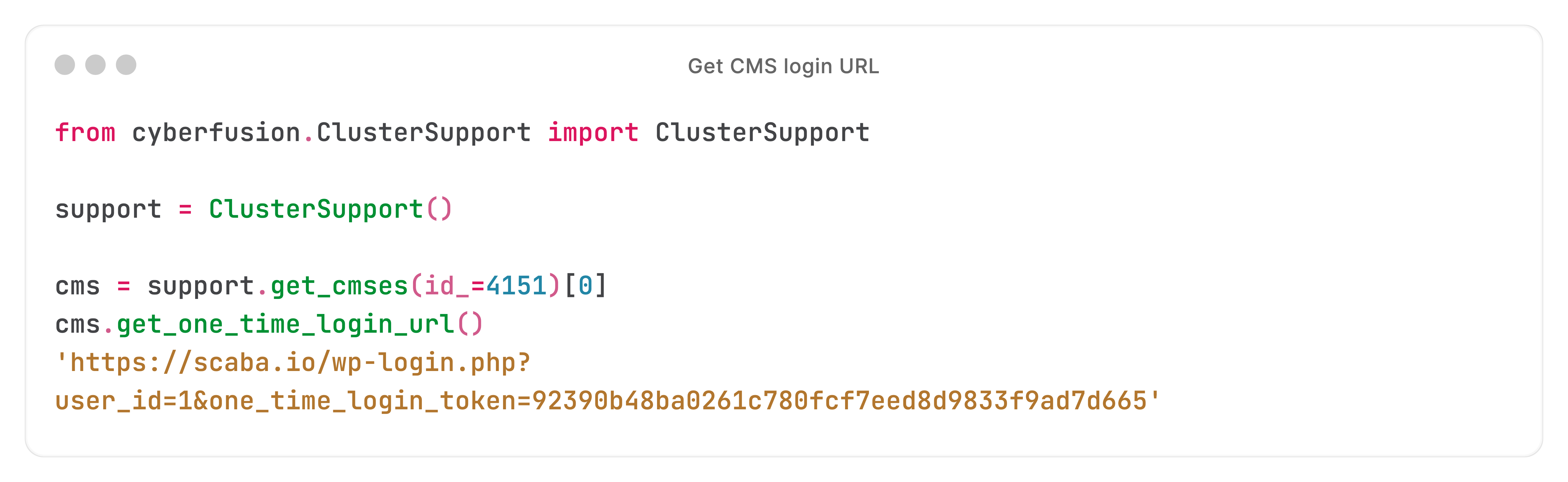
We hebben net een API (REST) call naar de Core API gedaan, en kregen een login-URL terug.
Maar de Core API weet niets van WordPress' implementatie - en heeft geen toegang tot de CMS-instantie.
Dus hoe genereerden we die URL on-the-fly?
Simpel gezegd:
- De Core API ontvangt onze request. Vervolgens wordt een RPC-call gedaan naar één van de nodes in het cluster.
- De node reageert met de login-URL. De Core API 'sanitised', valideert en returned het antwoord. Je merkt een gat in de implementatie - straks komen we op hoe de node aan de URL is gekomen.
Laten we bij het begin beginnen: hoe komt de RPC-call van de Core API terecht op de cluster-node?
RPC-calls worden 'brokered' door RabbitMQ: de Core API heeft vanwege schaalbaarheid en veiligheid niet direct toegang tot cluster-nodes.
Met de AMQP-interface van RabbitMQ kunnen we bidirectionele RPC-berichten (request-response) publiceren.
Laten we naar de code kijken.
Eerst verbindt de Core API met RabbitMQ:

De Core API maakt vervolgens een channel op de connection:

Nu we een channel hebben, publiceren we de request, en subscriben we op de response.
Eerst maken en binden we op een callback queue. De response wordt door de consumer naar deze queue gepubliceerd (daarover later meer).
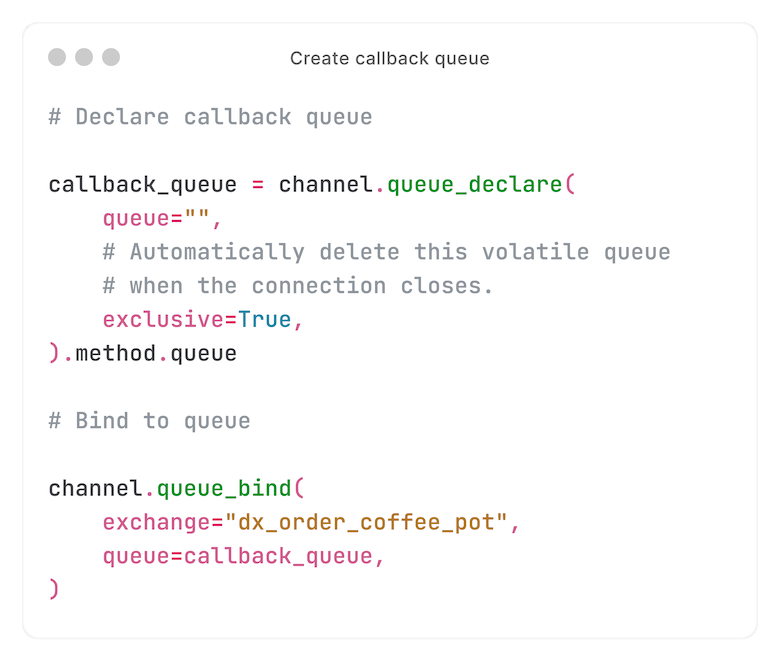
We publiceren naar een queue genaamd `dx_order_coffee_pot` - of, voor het voorbeeld van de login-URL: `dx_wordpress_installation_one_time_login_url`.
In RabbitMQ is een exchange een vrije, logische scheiding.
In de context van RPC, komt een exchange meestal overeen met een actie. Zoals een `POST /api/v1/coffee-pots/{id}/order` REST-endpoint.
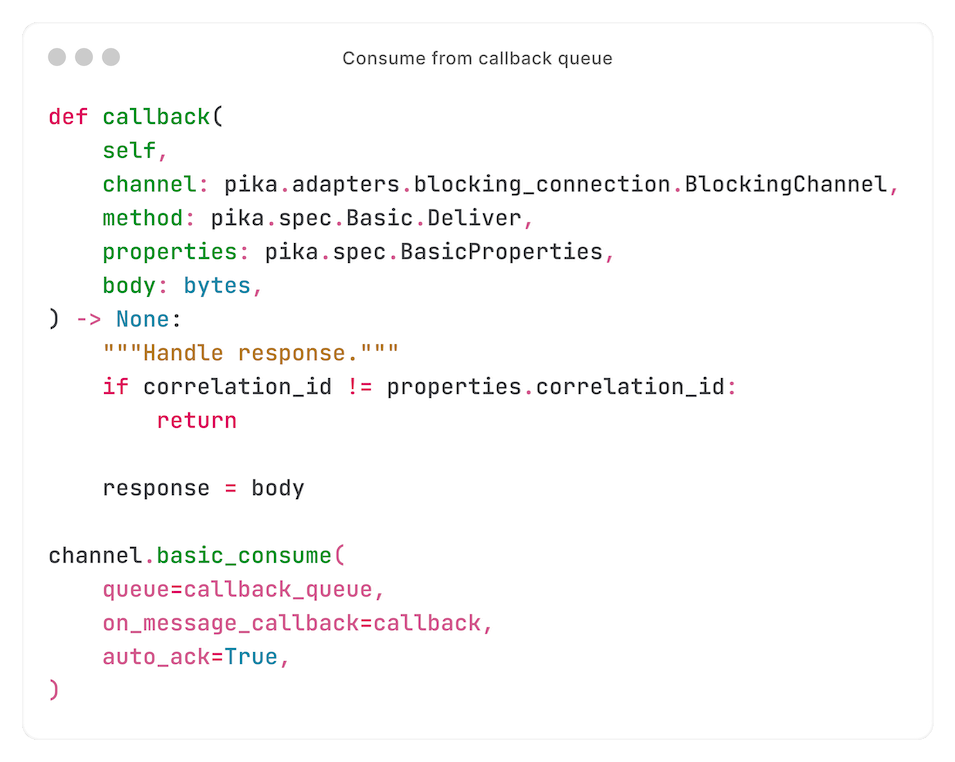
Nu we een callback queue hebben waarnaar de response kan worden gepublished, beginnen we van die queue te consumen - en wachten dus op de response:
Nu alles klaar is om de response te ontvangen, publishen we de request:

We hebben de request gepublished, en wachten op een response.
Als je goed oplet, zie je dat - toen we van de callback queue begonnen te consumen - we Pika (RabbitMQ-client) opdracht gaven om de `callback`-functie uit te voeren.
Wanneer een response wordt ontvangen, controleert deze functie de 'correlation ID' - zodat we zeker weten dat de response bij deze request hoort.
Als de 'correlation ID' overeenkomt, zet de functie de variable `response` - op dat punt is de `while`-loop broken.
Waar kwam de response vandaan?
Na het publiceren van de request, ontvingen we een response op de callback queue.
De response kwam van een consumer.
Elke cluster-node draait er één (of meerdere; daarover later meer).
Bekijk deze voorbeeld-configuratie om te begrijpen hoe de consumer werkt:
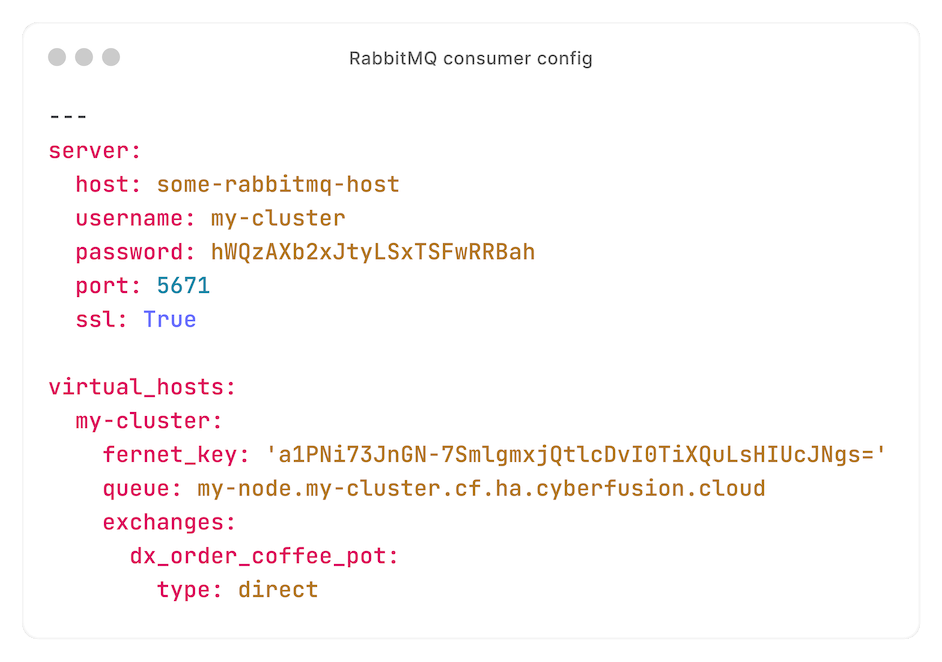
Met deze configuratie, consumen we van de exchange `dx_order_coffee_pot` - waarnaar we eerder een request hebben gepubliceerd.
Iedere node heeft een eigen queue, waardoor we requests naar specifieke nodes kunnen publiceren met routing keys.
Eerst binden we de queue van de lokale node aan alle geconfigureerde exchanges:
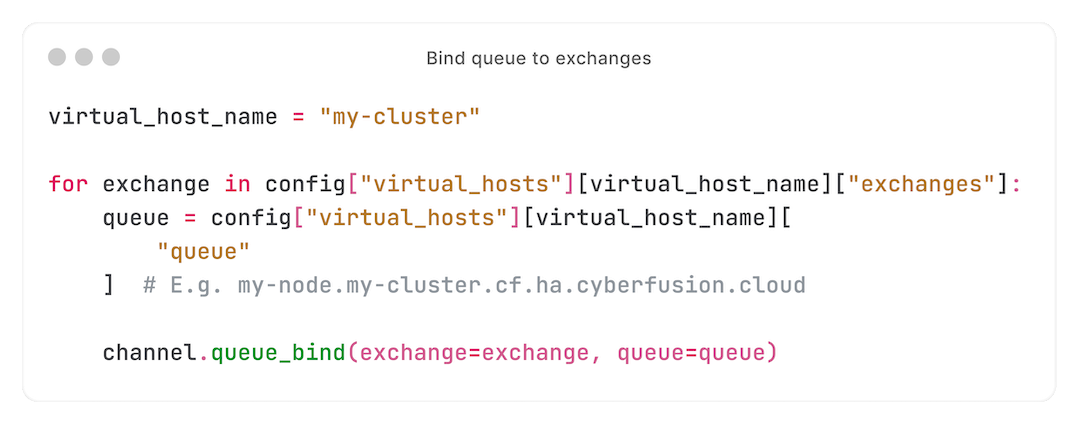
Daarna consumen we van onze queue:
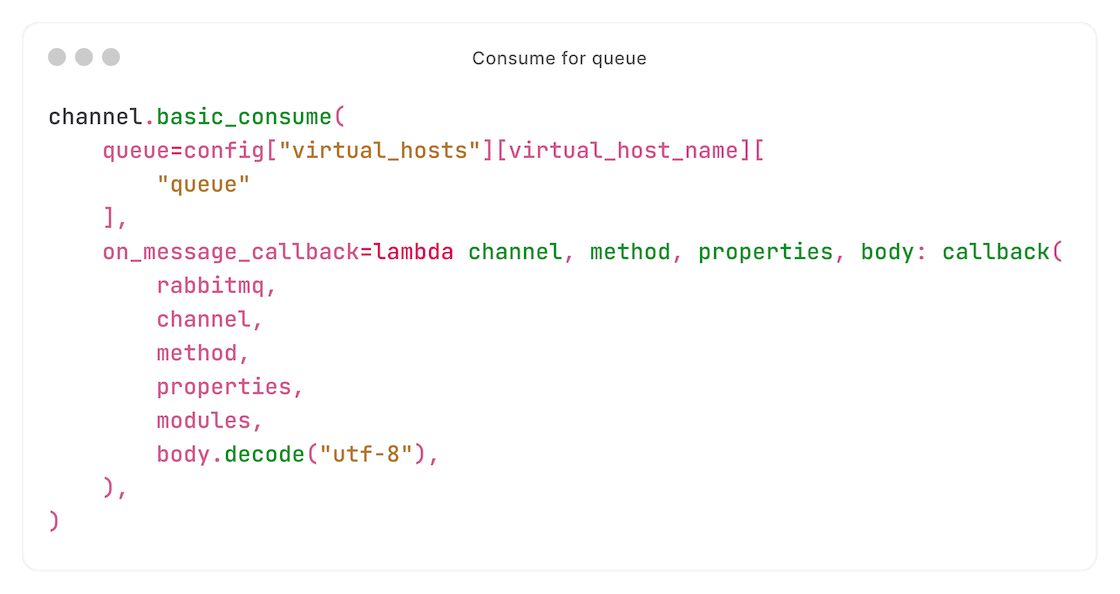
We ontvangen nu requests die bedoeld zijn voor deze node (messages waarvan de routing key identiek is aan de geconfigureerde queue, die identiek is aan de hostname van de node).
Wanneer een request wordt ontvangen, wordt de functie `callback` aangeroepen. Dat brengt ons bij het meest interessante deel...
Requests afhandelen
Voordat we dieper duiken in de `callback`-functie - die de request verwerkt - moet je één ding weten over scheiding.
Zoals we eerder uitlegden, komt een exchange overeen met een specifieke actie. Een request op de exchange `dx_order_coffee_pot` zorgt er bijvoorbeeld voor dat er een koffiepot wordt besteld.
Maar de consumer weet niet hoe: dat zou separation of concerns schenden.
In plaats daarvan, delegeert de `callback`-functie (die wordt uitgevoerd bij het ontvangen van een request) de logica naar een 'handler' per exchange. Deze handlers worden los van de consumer geïnstalleerd.
Wanneer we de consumer starten, importeren we handlers:

In zijn meest basale vorm - zonder locking, sanitising, threading, en verdere scheiding - ziet de `callback`-functie er zo uit:

En een handler ziet er zo uit:

Zoals je kunt zien, heeft de consumer het verwerken van de request gedelegeerd aan de handler, waarna de handler het verzoek delegeert aan een library.
Ergo: handlers zijn heel schaalbaar en 'maintainable'.
Handlers schalen: namespace packaging
Zoals eerder aangegeven, worden handlers apart van de consument geïnstalleerd.
Maar handlers worden ook los van elkaar geïnstalleerd. Handlers voor WordPress, bijvoorbeeld, zijn niet aanwezig op een node die niets met WordPress van doen heeft.
Als je goed hebt opgelet, heb je gezien dat we exchanges importeren van `cyberfusion.RabbitMQHandlers.exchanges` - een statische module.
Hoe voegen we handlers van meerdere packages dan toe aan dezelfde module?
Het antwoord: namespace packages. Python beschrijft ze als:
"Namespace packages allow you to split the sub-packages and modules within a single package across multiple, separate distribution packages (referred to as distributions in this document to avoid ambiguity)."
Met andere woorden: met namespace packages kunnen we handlers vanuit meerdere Python-packages installeren, terwijl ze dezelfde namespace hebben - zodat de consumer ze van een statische module kan importeren.
Ultieme veiligheid: gescheiden users en virtual hosts
Voordat we naar het laatste deel kijken (encryptie), eerst een blik op een andere vorm van beveiliging: scheiding.
Ieder cluster krijgt een eigen RabbitMQ virtual host. Iedere virtual host op een RabbitMQ-instantie is volledig gescheiden - waarom dat een goed idee is, hoeven we dus niet uit te leggen.
Maar er is nog een factor. Sommige requests, zoals een CMS installeren, draaien als de UNIX user aan wie het object toebehoort - volgens het principle of least privilege.
Privileges droppen met `setuid` en `setgid` is zo gedaan. Maar deze aanpak leverde problemen op:
- In zeldzame gevallen, garandeert privileges droppen niet dat ze later niet weer geüpgraded kunnen worden. Zulke kwetsbaarheden vermijden we, koste wat het kost.
- Algemene onhandigheden met environment en environment-variables.
Dus kiezen we ervoor om een consumer per UNIX user te draaien, draaiende als die UNIX user, zonder privileges te hoeven droppen.
Hoe je dat schaalbaar doet? systemd targets, met de `%i`-specifier - waarmee we meerdere units met een enkele unit-file kunnen draaien:

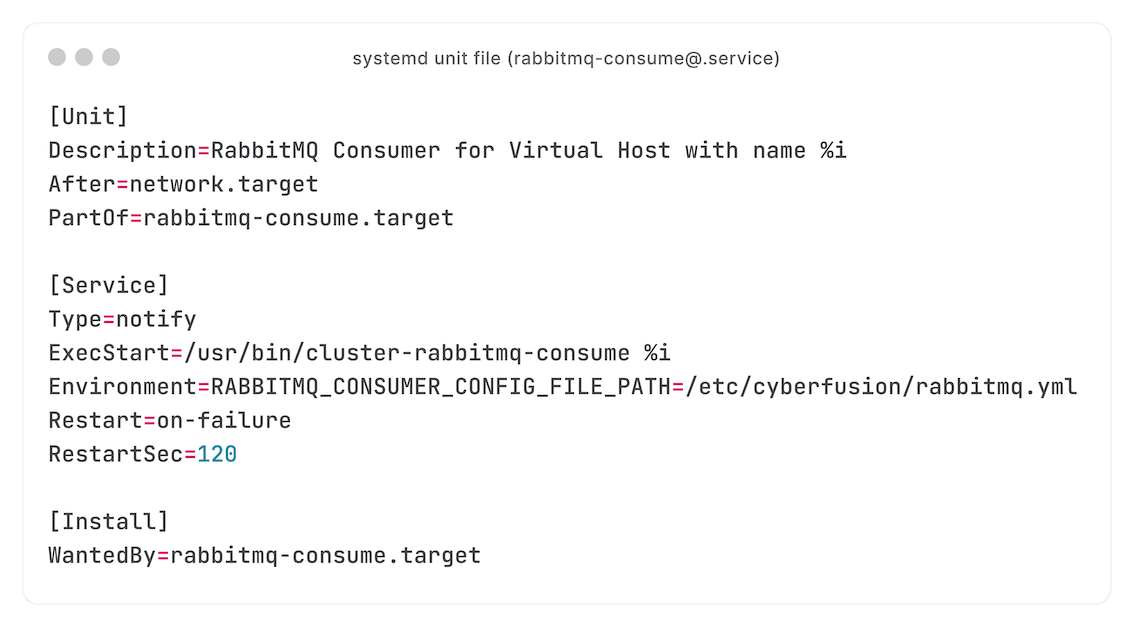
Met drop-in-files krijgt iedere consumer een eigen configuratie:

Een consumer per UNIX user draaien werkt goed, maar het kost veel RAM. Een 'idle' consumer gebruikt ongeveer 28 MB - reken maar uit voor clusters met honderden UNIX users. Maar de veiligheid is het waard.
Door het aantal processen op clusters met veel UNIX users, kunnen er problemen ontstaan als de consumer target herstarten wordt - alle consumers worden tegelijkertijd gestopt en gestart. We onderzoeken systemd's faciliteiten om de doorvoer van zo'n bulk-restart te vertragen of beperken.
Tot slot: we gaan nog verder dan een consumer per UNIX user: iedere UNIX user krijgt ook een eigen virtual host. Duizenden virtual hosts op een enkele RabbitMQ-instantie is geen veelvoorkomende use-case, maar uit onze ervaring blijkt dat het goed werkt - hoewel queues recoveren tijdens starten minutenlang kan duren.
Celery's kwargs beschermen met Fernet
Soms is een RPC-call deel van een task collection binnen Celery.
RPC-calls binnen Celery-tasks werken goed, maar we kwamen één probleem tegen: hoewel args en kwargs veilig aan RabbitMQ doorgegeven kunnen worden (de verbinding is encrypted), zouden ze plaintext in Celery's result backend worden opgeslagen.
Dat is natuurlijk geen optie. We overwogen om specifieke kwargs te removen of masqueraden, maar dat is een fragiele hack - op zijn best.
Fernet is onze oplossing: een symmetrische encryption-library, onderdeel van pyca's `cryptography`.
Voordat we een confidentiële kwarg aan Celery passen, encrypten we die:

In de consumer decrypten we die met dezelfde Fernet-key:
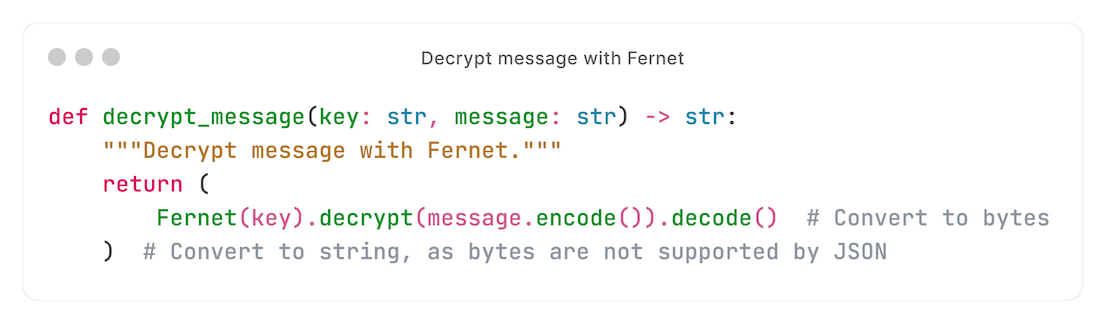
Het resultaat: opgeslagen kwargs zijn encrypted.
The result
Onze combinatie van RPC, RabbitMQ en dynamische handlers werkt extreem goed - zeker met Celery.
Wat dit project bijzonder interessant maakt, is dat het 'doorsnee' API-programmeren combineert met het Linux-ecosysteem - DevOps op zijn best.
Hoewel we heel trots zijn op dit project, kunnen dingen altijd beter. Eigenlijk alleen de consumer heeft een paar to-do's. De belangrijkste: cross-exchange locks. Overlappende acties vertragen we (bijvoorbeeld hetzelfde CMS twee keer tegelijkertijd installeren). Maar wat als een gebruiker de cache probeert te flushen voor een CMS dat geïnstalleerd wordt? Of wat als een user honderden FPM-pools tegelijkertijd probeert te herstarten? Nu we deze setup een paar maanden draaien, zijn we in de praktijk heel veel interessante gevallen tegengekomen - waarvoor we de implementatie perfectioneren.
En dat brengt ons op de nodige link naar onze vacatures.