Hosting-infrastructuur bouwen anno 2024: configuratie-management (deel 1)
Hosting-infrastructuur bouwen anno 2024: configuratie-management (deel 1)
De afgelopen tweeënhalf jaar bouwen we dag in, dag uit aan ons WebOps-platform ('web operations'). Daarmee kunnen web-professionals vele websites en applicaties hosten, monitoren, beveiligen en optimaliseren. Zowel wij als onze klanten zijn heel enthousiast over de nieuwe mogelijkheden. Maar hoe je het ook went of keert: het begint allemaal bij stabiele hosting.
We willen de touwtjes in handen hebben. Daarom bouwen we onze hosting-infrastructuur zelf, op basis van cluster-technologie. Hoe we dat doen leggen we graag uit in een serie van artikelen. Waarom? Niet alleen omdat we techniek heel leuk vinden (want dat vinden we). Maar bovenal denken we dat het zinvol is om elkaar - Europese bedrijven die een alternatief vormen voor de gevestigde orde uit Amerika - te inspireren. Door techniek niet als 'black box' te zien, maar open te zijn en ideeën te delen.
Als eerste in de serie: configuratie-management voor clusters.
Allereerst: waarom clustering?
Met een cluster draait een website of applicatie niet op een enkele server, maar op meerdere. Een server noemen we dan een 'node'. Valt een node uit? Geen probleem, dan neemt een ander het over. Ineens heel veel bezoekers? Geen stress, alle nodes samen kunnen dat aan. Ideaal dus, maar ook een stuk complexer: clustering is standaard voor bedrijfskritische omgevingen, maar niet voor websites en applicaties. Bij ons wel: of een klant nou een simpele WordPress-website of een complexe Laravel-applicatie heeft.
Nu wordt het lekker technisch. Want zoals je hebt kunnen lezen biedt clustering heel veel voordelen, maar het is beduidend complexer. Want alle nodes in een cluster moeten geconfigureerd zijn om een website of applicatie te serveren, in plaats van een enkele server. Wat voor uitdagingen krijg je dan?
- Hoe garandeer je dat alle nodes identiek geconfigureerd zijn? En wat als je een node toevoegt?
- Hoe zorg je ervoor dat wijzigingen snel op meerdere nodes worden doorgevoerd?
- Wat als het doorvoeren van een wijziging op één node mislukt? Stop je dan?
- Hoe garandeer je dat wijzigingen serieel (één-voor-één) doorgevoerd worden? Als je het op alle nodes tegelijkertijd doet, kan een foutieve wijziging alle nodes in het cluster om zeep helpen.
Enter: een zelfgebouwd configuratie-management-systeem
Op 21 februari 2023 zag een nieuw Python-project het levenslicht: 'cluster-configuration-manager'. Geen inspirerende naam, maar wel doeltreffend: een configuratie-management-systeem voor clusters. Sommigen zullen denken: een eigen configuratie-management-systeem? Is dat niet het wiel opnieuw uitvinden? Maar wees gerust: we doen niet álles zelf. Zo gebruiken we meerdere bestaande tools:
- etcd vormt de basis, een gedistribueerde key-value-store die 'primitives' biedt om gedistribueerde acties te coördineren. Een hele mond vol, maar simpel gesteld: etcd biedt bouwblokken en garanties om wijzigingen op meerdere nodes door te voeren, maar nooit tegelijkertijd. Kubernetes gebruikt het ook intensief.
- Ansible voor sommige wijzigingen, zoals PHP-versies toevoegen en verwijderen. Deze playbooks worden aangeroepen vanuit 'cluster-configuration-manager'. Voor meer eenvoudige wijzigingen, zoals het schrijven naar files, gebruiken we eigen libraries. Die kunnen wijzigingen voorvertonen, met diffs. Zo kunnen we zien wat er zou gebeuren, zonder iets mogelijk stuk te maken.
Ik werk iets bij... en dan?
Terug naar 'cluster-configuration-manager' zelf. Het leuke eraan is: het zit op het snijvlak van development en operations. Want de code zelf gebruikt geaccepteerde code-'patterns' (interfaces, factories, enzovoort), maar wat eruit komt zijn bijvoorbeeld nginx- en Dovecot-configuraties. Wat er in die configuraties staat, bepaalt de Core API: de API om clusters te beheren. Wijzigt daar iets, dan gaan alle nodes de wijziging verwerken:
- In de Core API wordt een object gemuteerd. Laten we zeggen dat een klant een cron aanmaakt.
- De Core API updatet een etcd-key met dezelfde naam als het object-type. In dit geval dus 'cron'.
- Op iedere node draait een 'etcd watcher'. Wordt een etcd-key geüpdatet? Dan weten we dat er iets moet gebeuren. Dit noemen we een 'thin event'.
- De watcher wacht 10 seconden. Is er in de tussentijd nog een mutatie? Dan wachten we weer. Totdat er 10 seconden lang niets gebeurt. Door deze 'delay' worden wijzigingen in bulk uitgevoerd, waardoor services maar één keer hoeven te 'reloaden'.
- De watchers op alle nodes vragen een lock aan ('acquire'). Slechts één node kan de lock hebben. Die node voert de wijzigingen door. Klaar? Dan wordt de lock vrijgegeven ('release'). En krijgt de volgende node de lock. Totdat alle nodes de wijzigingen één voor één verwerkt hebben. Dit alles met 'distributed locking' van etcd.
- Mislukt er iets? Dan zet de watcher een flag. De andere nodes weten dan dat ze de wijzigingen niet moeten verwerken.
Kortom: alle uitdagingen van eerder - zoals wijzigingen serieel doorvoeren, en nodes identiek configureren - zijn van tafel.
Hieronder een schematische weergave van bovenstaande stappen.
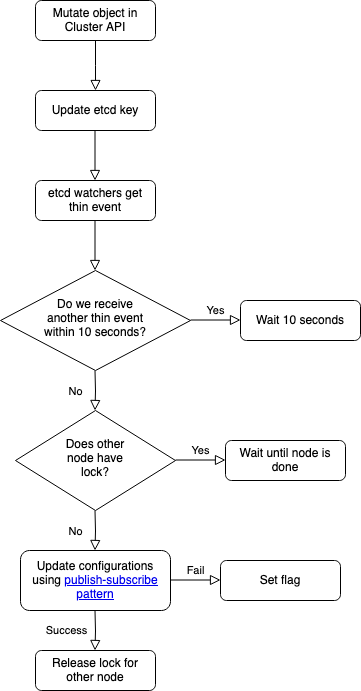
Flowchart van mutatie
Geen verrassingen: 'deterministic' en 'reproducible' configuraties
Onze aanpak heeft nog een groot voordeel. Stel dat een cron wordt gemuteerd. Dan weten we maar één ding: er is iets veranderd aan crons. Wat? Geen watcher die het weet. Maar dat maakt ook niet uit. Want telkens worden configuraties helemaal opnieuw gedraaid. Dat klinkt misschien inefficiënt, maar daardoor zijn er nooit verrassingen:
- Maak je iets stuk? Draai de configuratie, dan werkt het weer. Configuratie weggegooid? Geen probleem, die komt vanzelf terug. Wat je doet ook doet: configuraties op nodes raken altijd weer in de verwachte staat.
- Nodes zijn gegarandeerd identiek geconfigureerd. Voeg je een node toe? Die ook. Enkel door de configuraties te draaien. Laat zelfs de meest doorgewinterde DevOps Engineer de verschillen maar eens zoeken!
- We hoeven niets te 'parsen'. Stel: een klant voegt een cron toe. In plaats van de crontab parsen, cron toevoegen en opslaan, overschrijven we de crontab met de verwachte inhoud. Nul kans dat er iets misgaat bij het parsen. En dus nul kans op een corrupte configuratie. Een heel scala aan mogelijke bugs - waar bestaande controlepanelen vaak door geplaagd worden - direct uitgesloten.
'But does it scale?': pub/sub
We missen nog één cruciaal onderdeel. In het voorbeeld hebben we een cron bijgewerkt. Op iedere node moeten dan meerdere dingen worden bijgewerkt. Een configuratiebestand met een e-mailadres voor foutmeldingen. Maar ook de user crontab. En daarna moet nog een commando draaien. Declareren we dat allemaal op één plek, dan wordt het heel onoverzichtelijk. Zeker met tientallen object-types en honderden configuraties.
Daarom gebruiken we het 'publish-subscribe pattern', ook bekend als 'pub/sub'. Iedere configuratie abonneert zichzelf op een object-type. Zo abonneert de configuratie 'CronTab' zich op het object-type 'crons'. En 'PHPConfigurationFile' op 'fpm-pools'. Daardoor weet de watcher: wordt een bepaald object-type gemuteerd, dan moeten de geabonneerde configuraties draaien.
Technischer verwoord: zodra de watcher een 'thin event' ontvangt, 'publisht' die een 'event' op een 'event bus' en vermeldt daarin het object-type, waarna de 'subscribed' configuraties draaien.
'I did not expect that': volgorde van dependencies
In maart 2023 ging de eerste versie van 'cluster-configuration-manager' live. En trots waren we. Maar alle IT'ers kunnen beamen: je vergeet of onderschat altijd iets. Wij ook. We kwamen al snel in de knoei met dependencies. Bijvoorbeeld: we moeten eerst een user aanmaken, dan pas een home-directory. Klinkt simpel. Maar niet met honderden configuraties:
- Veel configuraties = circulaire dependencies. Bijvoorbeeld: A is afhankelijk van B, B van C, en C van A. Dat kan natuurlijk niet.
- Volgorde van declareren. Declareren we eerst B en daarna A, dan mag B niet afhankelijk zijn van A. Want op het moment dat we B declareren, kent de code A nog niet.
We hebben dit opgelost met topologische sortering. Geen simpel algoritme, wel een simpel idee: in welke volgorde je ook declareert, en welke dependencies je ook hebt... ze worden correct gesorteerd. Voor Python was al een goede library beschikbaar; scheelt een hoop complexiteit!
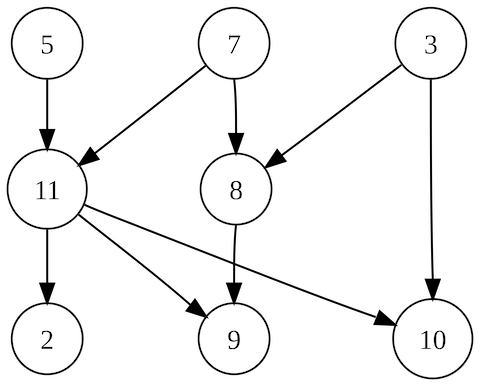
In dit voorbeeld kan op verschillende manieren topologisch gesorteerd worden. Bijvoorbeeld 5, 7, 3, 11, 8, 2, 9, 10. Maar ook 3, 5, 7, 8, 11, 2, 9, 10. Bron: https://en.wikipedia.org/wiki/Topological_sorting#/media/File:Directed_acyclic_graph_2.svg
Wat kan er nog beter?
Zoals je hebt kunnen lezen, zijn we goed op weg met onze hosting-infrastructuur. Maar we zijn nog niet klaar. We blijven doorbouwen, dus dat zal ook nooit zo zijn. Maar sommige dingen staan wel hoog op de to-do-lijst:
- Meer features bouwen! We hebben veel gave ideeën. Van Varnish-support tot autoscaling. Geen probleem dankzij de modulaire opzet van 'cluster-configuration-manager'. Kijk eens op onze roadmap.
- etcd is een project van Google, en heeft dus een uitstekende client voor hun programmeertaal Go. De community-maintained Python-client is iets ruwer. Misschien forken we die.
- Tests. Hoewel de watcher - ook zelfgebouwd - geautomatiseerd wordt getest, is het een uitdaging om deze nóg uitgebreider te testen door onder andere threading en 'double-ended queues'.
Volgende keer: real-time tasks
In het volgende deel, gaan we in op real-time tasks. Zoals nodes upgraden en back-ups terugzetten. Hoe gaat dat in een cluster? En hoe houd je dat - ook met duizenden users - veilig en schaalbaar?