Building hosting infrastructure in 2024: RPC actions (part 3)
Building hosting infrastructure in 2024: RPC actions (part 3)
Installing a CMS. Restarting an FPM pool. Restoring a backup.
These actions have two things in common: they run in real-time, and require things to run on cluster nodes.
How? RPC through RabbitMQ (AMQP). Let's take a look.
Let's take a random real-time action: getting a WordPress website's login URL:
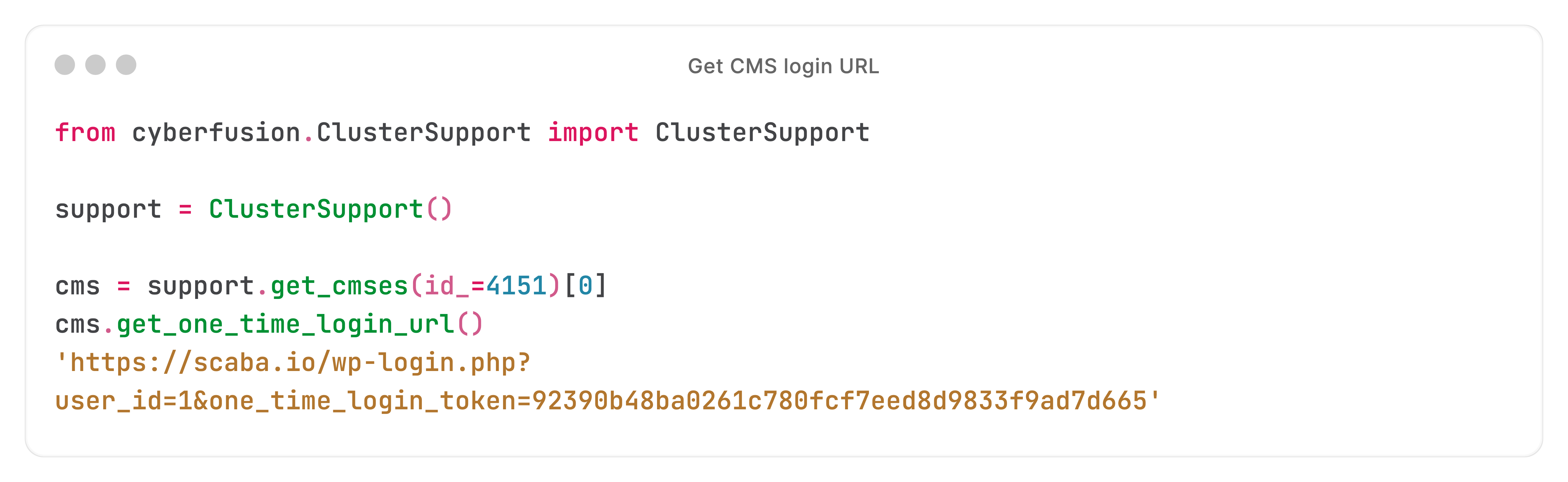
We just did an API (REST) call to the Core API, and got back a login URL.
But the Core API doesn't know anything about WordPress' implementation - nor does it have access to the CMS instance.
Simply put:
- The Core API gets our request. It then does an RPC call to one of the nodes in the cluster.
- The node answers with the login URL. The Core API sanitises, validates and returns the answer. You'll notice a gap in the implementation - hang on for how the node got the URL.
Let's start at the beginning: how does the Core API's RPC call end up on the cluster node?
RPC calls are brokered by RabbitMQ - the Core API can't access cluster nodes directly, for scalability and security reasons.
Using RabbitMQ's AMQP interface, we can publish bidirectional RPC (request-response) messages.
Let's see the code.
First, the Core API connects to RabbitMQ:

It then creates a channel on the connection:

Now that we have a channel, let's publish the request, and subscribe to the response.
First, we create and bind to a callback queue. The response will be published to this queue by the consumer (more on that later).
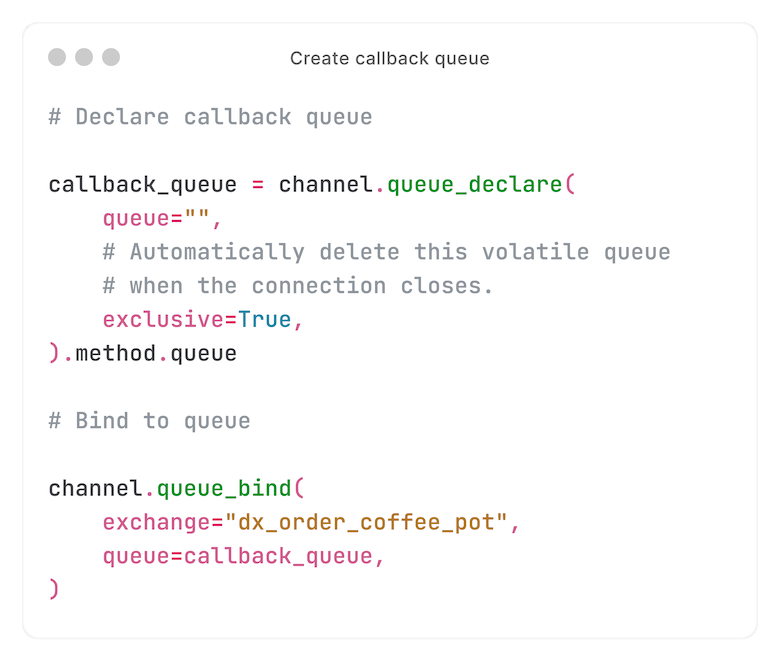
We're publishing to an exchange called `dx_order_coffee_pot` - or, for the login URL example: `dx_wordpress_installation_one_time_login_url`.
In RabbitMQ, an exchange is a free-form logical separation.
In an RPC context, an exchange usually corresponds to an action. Like a `POST /api/v1/coffee-pots/{id}/order` REST endpoint.
Now that we have a callback queue that the response can be published to, we start consuming from it - therefore awaiting the response:
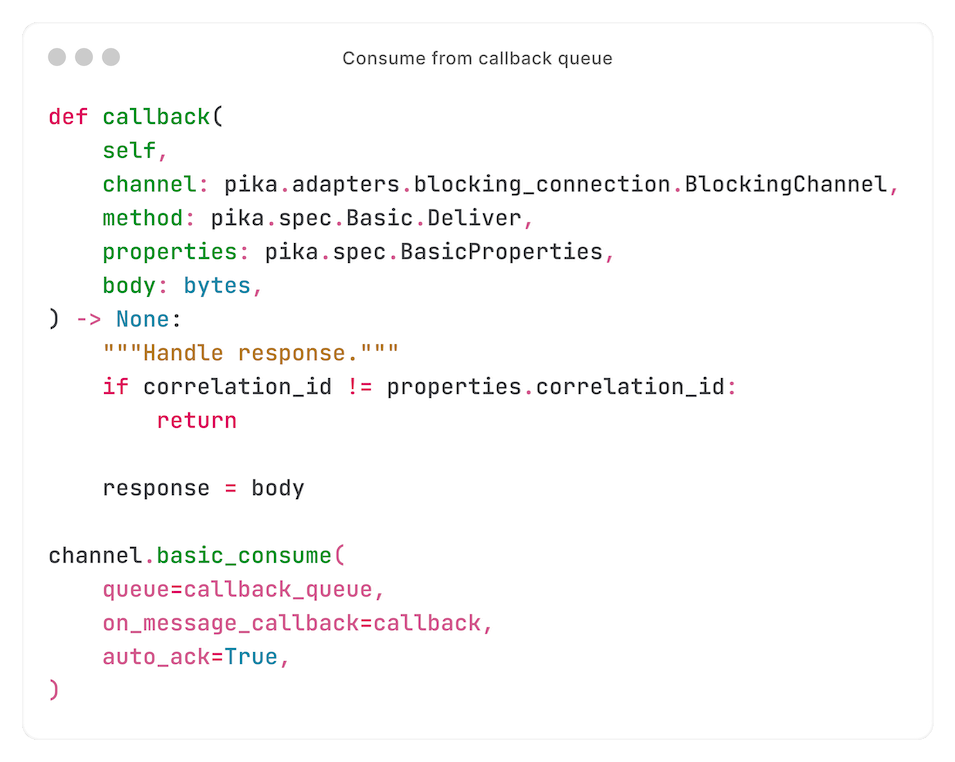
Now that everything's in place to capture the response, we publish the request:

We've published the request, and are waiting for a response.
If you paid close attention, you saw that when we started consuming from the callback queue, we instructed Pika (RabbitMQ client) to run the `callback` function.
When a response is received, this function checks the correlation ID - ensuring that the response belongs to this request.
If the correlation ID matches, the function sets the variable `response` - at which point the `while` loop will be broken.
Where did the response come from?
After publishing the request, we received a response on the callback queue.
The response came from a consumer.
Every cluster node runs one (or multiple; more on that later).
To understand how the consumer works, see this example configuration:
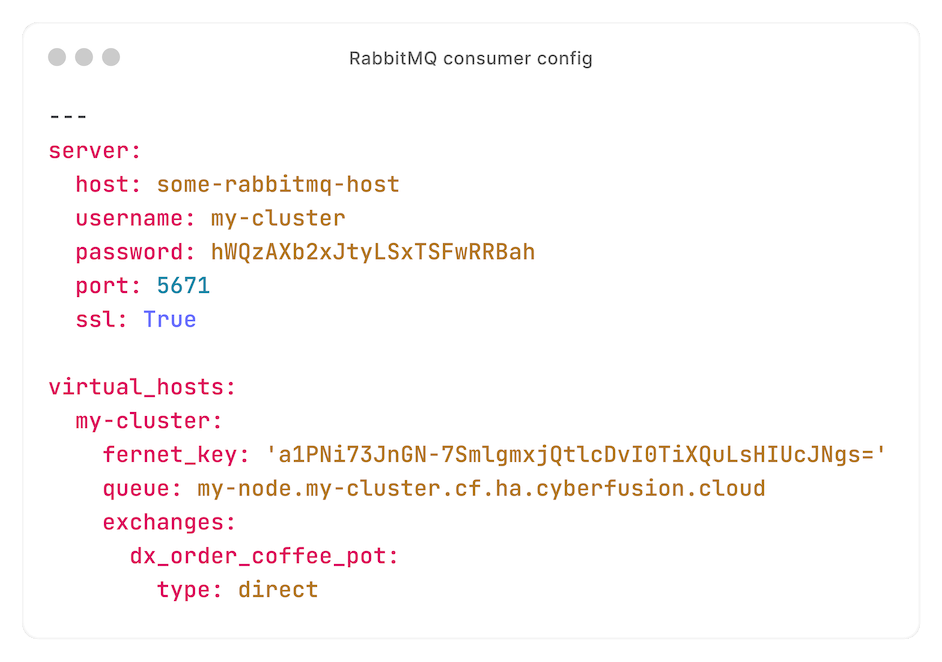
With this configuration, we consume from the exchange `dx_order_coffee_pot` - which we published a request to earlier.
Every node has its own queue - allowing us to publish requests to specific nodes using routing keys.
First, we bind the local node's queue to all configured exchanges:
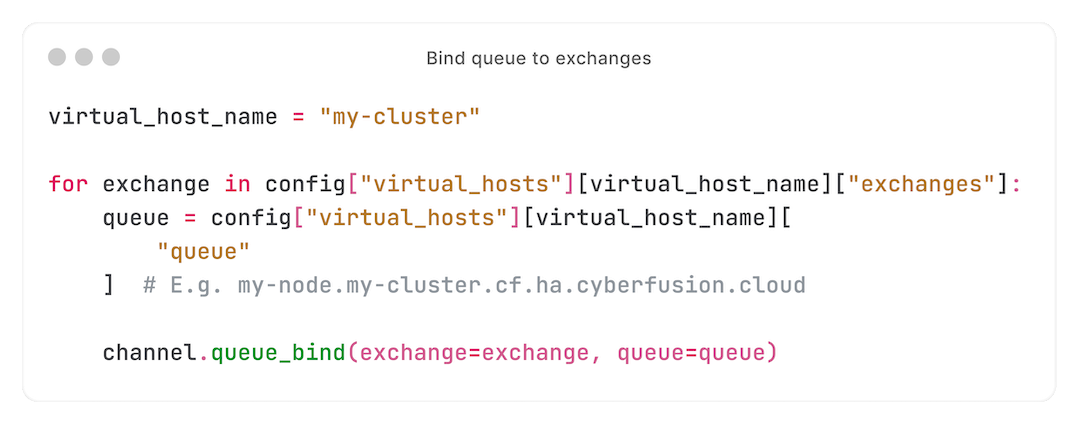
We then start consuming from our queue:
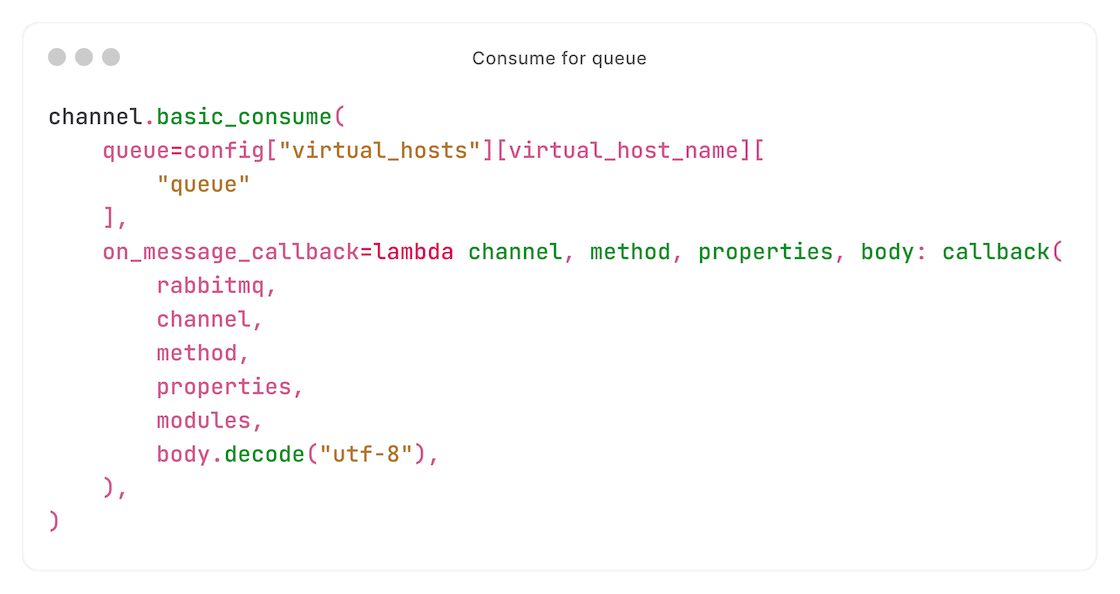
We are now receiving requests intended for this node (messages for which the routing key identical to the configured queue, which is identical to the node hostname).
When a request is received, the function `callback` is called. That brings us to the most interesting part...
Handling requests
Before we dive deeper into the `callback` function - which processes the request - you need to know one thing about separation.
As we explained earlier, an exchange corresponds to a specific action. For example, a request on the exchange `dx_order_coffee_pot` causes a coffee pot to be ordered.
But the consumer doesn't know how to: that would violate separation of concerns.
Instead, the `callback` function (which runs when receiving a request) delegates the logic to a per-exchange 'handler'. These handlers are installed separately.
When starting the consumer, we import handlers:

In its most basic form - excluding locking, sanitising, threading, and further separation - the `callback` function looks like this:

And a handler looks like this:

As you can see, the consumer delegated processing the request to the handler, after which the handler delegates it to a library.
Ergo: handlers are very scalable and maintainable.
Scaling handlers: namespace packaging
As mentioned before, handlers are installed separately from the consumer.
But handlers are also installed separately from each other. For example, handlers for WordPress aren't present on a node that has nothing to do with WordPress.
If you paid close attention, you will have seen that we import the exchange from `cyberfusion.RabbitMQHandlers.exchanges` - a fixed module.
So, how do we add handlers from multiple packages to the same module?
The answer: namespace packages. Python describes them as:
"Namespace packages allow you to split the sub-packages and modules within a single package across multiple, separate distribution packages (referred to as distributions in this document to avoid ambiguity)."
In other words: namespace packages let us install handlers from multiple Python packages, while adding them to the same namespace - so the consumer can import them from a fixed module.
Ultimate security: separated consumers, users and virtual hosts
Before we look at the final part (encryption), let's take a look at another type of security: separation.
Every cluster gets its own RabbitMQ virtual host. Every virtual host on a RabbitMQ instance is fully separated - so we don't need to explain why that's a good idea.
But there is another factor: some requests, such as installing a CMS, run as the UNIX user to which the object belongs - following the principle of least privilege.
Dropping privileges is easy with `setuid` and `setgid`. But we ran into issues with this approach:
- In rare cases, dropping privileges does not guarantee that they can't be upgraded later. We avoid such vulnerabilities at all costs.
- General clumsiness with environment and environment variables.
So, we decided to run a consumer per UNIX user, running as that UNIX user, without having to dropping privileges.
How do you keep that scalable? systemd targets, with the `%i` specifier - letting us run multiple units with a single unit file:

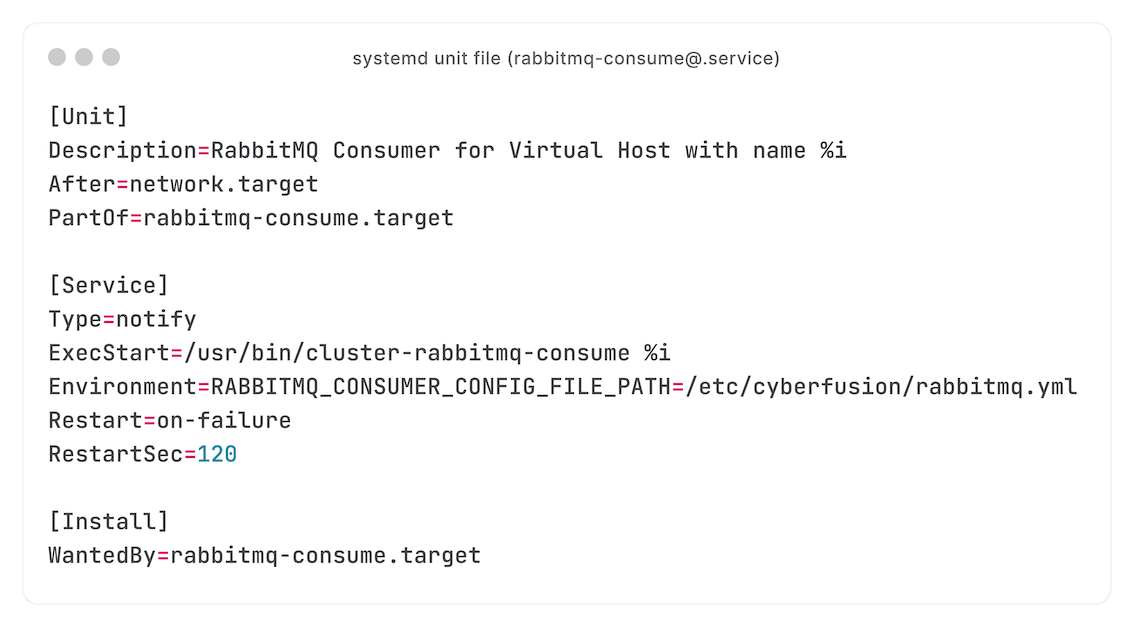
Using drop-in files, every consumer gets its own configuration:

Running a consumer per UNIX user works well, although it does cost quite some RAM. An idle consumer uses about 28 MB - do the math for clusters with hundreds of UNIX users. But the security is worth it.
Due to the sheer amount of processes on clusters with many UNIX users, restarting the consumer target can cause issues - all consumers are stopped and started simultaneously. We are investigating systemd's facilities to delay or limit the throughput of such a bulk restart.
Finally, we go even further than having a consumer per UNIX user: every UNIX user also gets its own virtual host. Having thousands of virtual hosts on a single RabbitMQ instance is not a common use case, but our experience shows that it works well - although recovering queues on startup can take several minutes.
Protecting Celery's kwargs using Fernet
Sometimes, an RPC call is part of a task collection run inside Celery.
Doing RPC calls inside Celery tasks works well, but we saw one issue: although args and kwargs can be passed to RabbitMQ safely (the connection is encrypted), they would be stored in plaintext in Celery's result backend.
Obviously, storing confidential data in plaintext is not an option. We considered removing or masquerading specific kwargs, but that's a fragile hack - at best.
Fernet is our solution: a symmetric encryption library, part of pyca's `cryptography`.
Before passing a sensitive kwarg to Celery, we encrypt it:

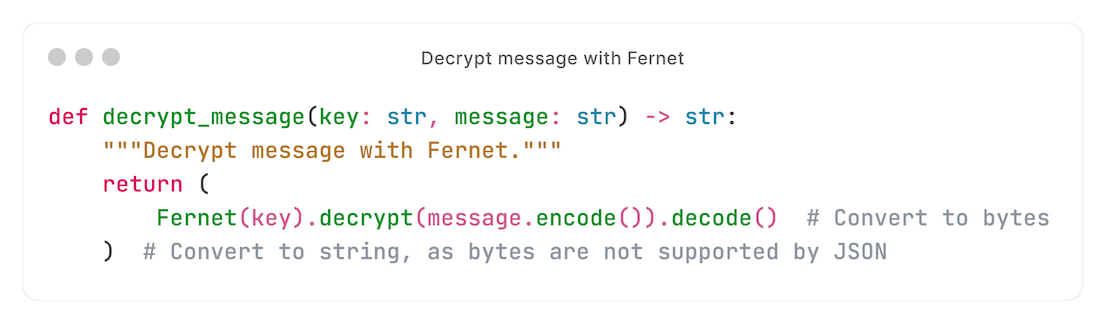
In the consumer, we decrypt it using the same Fernet key:
The result: stored kwargs are encrypted.
The result
Our combination of RPC, RabbitMQ and dynamic handlers works extremely well - also combined with Celery.
What makes this project especially interesting, is that it combines 'regular' API programming with the Linux ecosystem - DevOps at its best.
Although we're very proud of this project, things can always be improved. Really, only the consumer has a few to-dos. Most importantly: cross-exchange locks. We delay overlapping actions (for example, installing a CMS). But what if a user tries to flush the cache for a CMS that is currently being installed? Or what if a user tries to bulk-restart hundreds of FPM pools at once? Having run this setup for a few months, we've seen the most interesting cases in practice - for which we're perfecting the implementation.
And that brings us to the mandatory link to our openings.