Building hosting infrastructure in 2024: real-time tasks (part 2)
Building hosting infrastructure in 2024: real-time tasks (part 2)
On a hosting platform, things are happening real-time all the time: requesting certificates, restoring backups, upgrading nodes... you name it.
We self-built a task management system with which our users can start, follow and retry tasks - based on Celery and FastAPI.
This project makes our Python hearts beat faster, and we're very proud of the result. Let's dive in.
Where we are now
Before we dive into how our task system works technically, let's take a quick look at what it does.
Take the example of requesting a certificate:
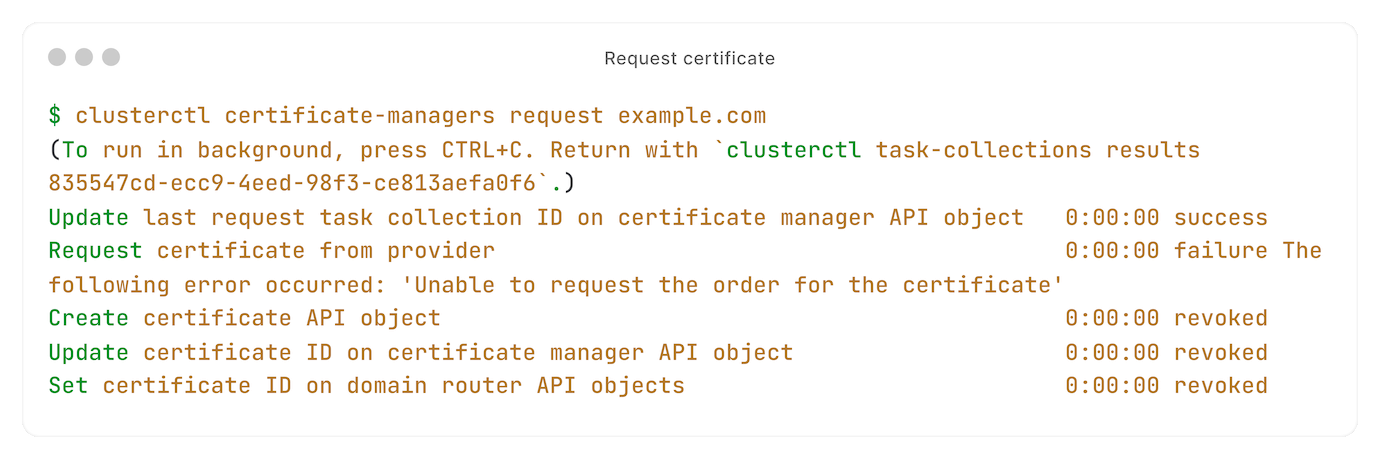
The tasks are run in the background, outside of the HTTP request-response cycle.
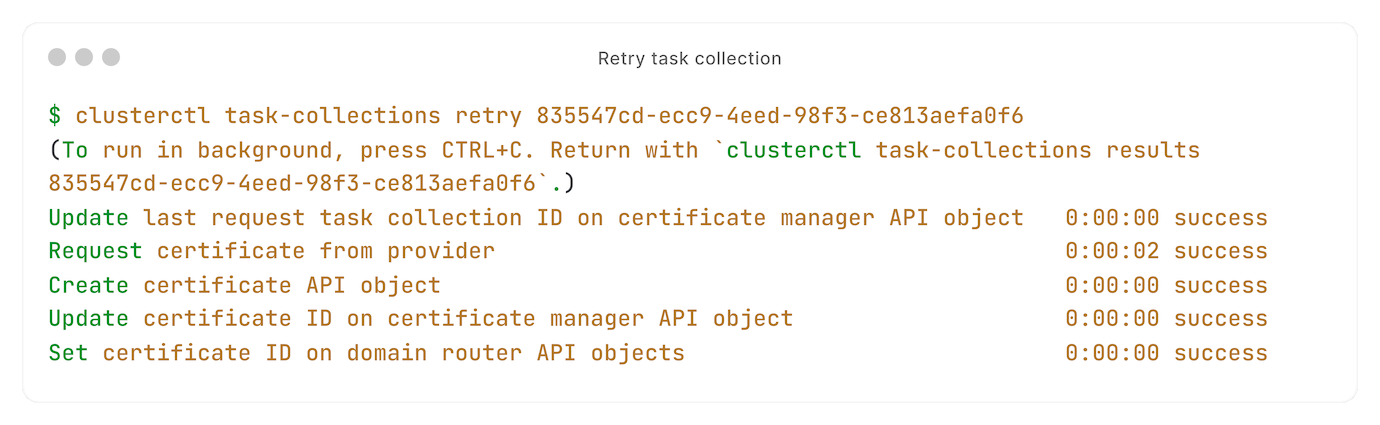
One of our tasks failed. No problem, that's why we have retries:
Want to see tasks after the fact? It's one command away:
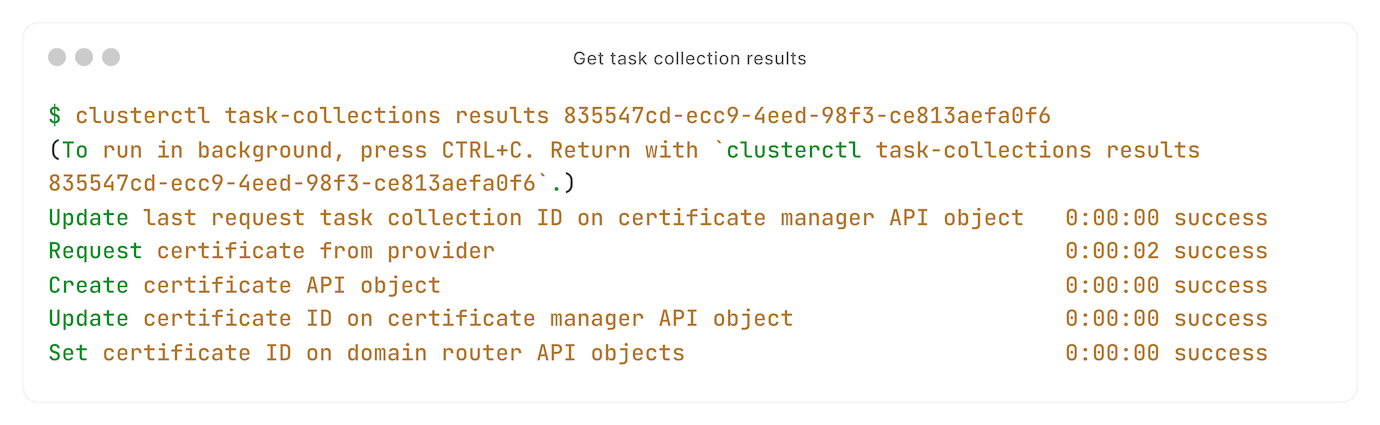
We didn't use any existing solutions, like django-celery or Laravel queues.
So how does it work? Let's look under the hood.
A love-hate relationship with Celery
To run tasks, we use Celery. A debatable yet common choice.
We are well aware of alternatives such as Prefect and Dramatiq - they learned from what Celery doesn't do so well.
But the simple fact is: nothing can beat Celery's stability. It's a mature project, with a stable API - and that's worth a lot in a professional environment.
With Celery in our toolbox, let's go to the interesting part: starting and following tasks with our FastAPI API.
Running tasks with Celery
All tasks should run one-by-one, in a specific order. We can't create a certificate if we can't request it first. We can't restore a backup if we can't download it first. You get the idea.
Celery has a built-in solution: chains.
A basic example:

In this example, we buy a table, then clean it.
We can't clean a table that we don't have. So the clean task is never reached if the buy task fails.
Before we move on to the next part, we had to deal with two peculiarities.
Number one: once a chain has been called, we can't easily ask Celery: "which tasks belong to this chain?". It's possible, but only by relying on semi-hidden implementation details.
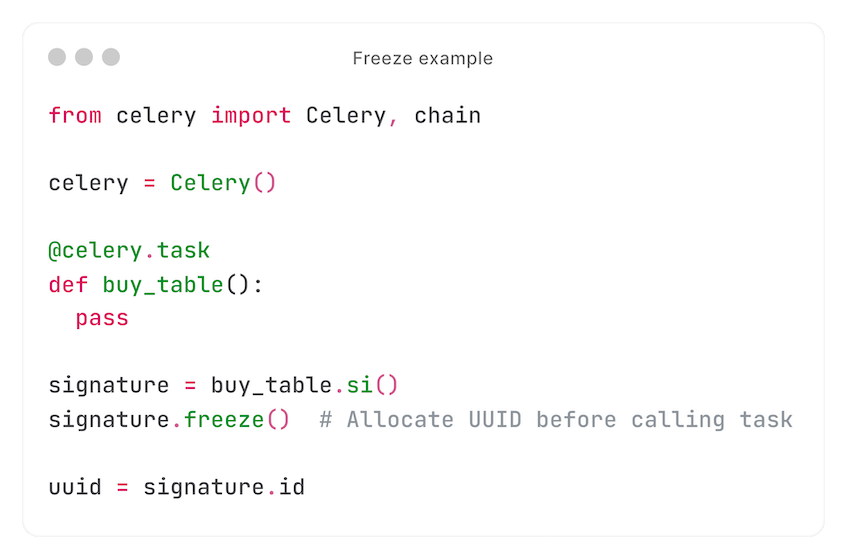
As a stable solution, we store the tasks belonging to a chain ourselves. First, we 'freeze' the signature to pre-allocate a UUID, which we save:
The second peculiarity: chains may have only a single task. It's rare, but can happen. We then add a 'dummy' task to make Celery consider this a chain.
In this specific case, we prefer this approach - having to maintain and test logic for rarely used code is usually an anti-pattern.

Retries in a flakey world
Following the earlier example: suppose we do an external API call to buy the table. What if that API is unreachable?
Our task will fail. And at some point, we want to retry.
It may not look like it, but this is the most complex part - by far. To understand why, you must know one thing: Celery supports retrying tasks, but not outside of a task.
For example, we can do this:

... but not this:

There are workarounds to get a task after running it. But even those don't solve our problem fully: only that task would be retried, not the chained tasks that come after it.
We came up with a creative solution.
When a user retries a task collection, we don't actually retry unsuccessful tasks. Instead, we create a new chain, with tasks identical to the unsuccessful ones - including the UUID, so our database 'automagically' points to the new tasks.
This requires some ingenious thinking.
First, when we create the original chain, we store everything we need to know about those tasks. Some information comes from extended results (kwargs, args, name, etc.), other information is stored in our database (signature immutability, etc.)

Callbacks for automation
Many users integrate the Core API with their own systems. For example, they may send notifications when a certificate request fails.
For that, we have callbacks.
Multiple API endpoints return a task collection. Every such endpoint accepts a callback URL.
When the callback URL is specified, a task is added to the chain - calling that URL. Using Celery's `on_error` function, that task is always executed - even when a task in the chain fails.

To document the callback body, we use OpenAPI's callbacks feature using FastAPI's integration:
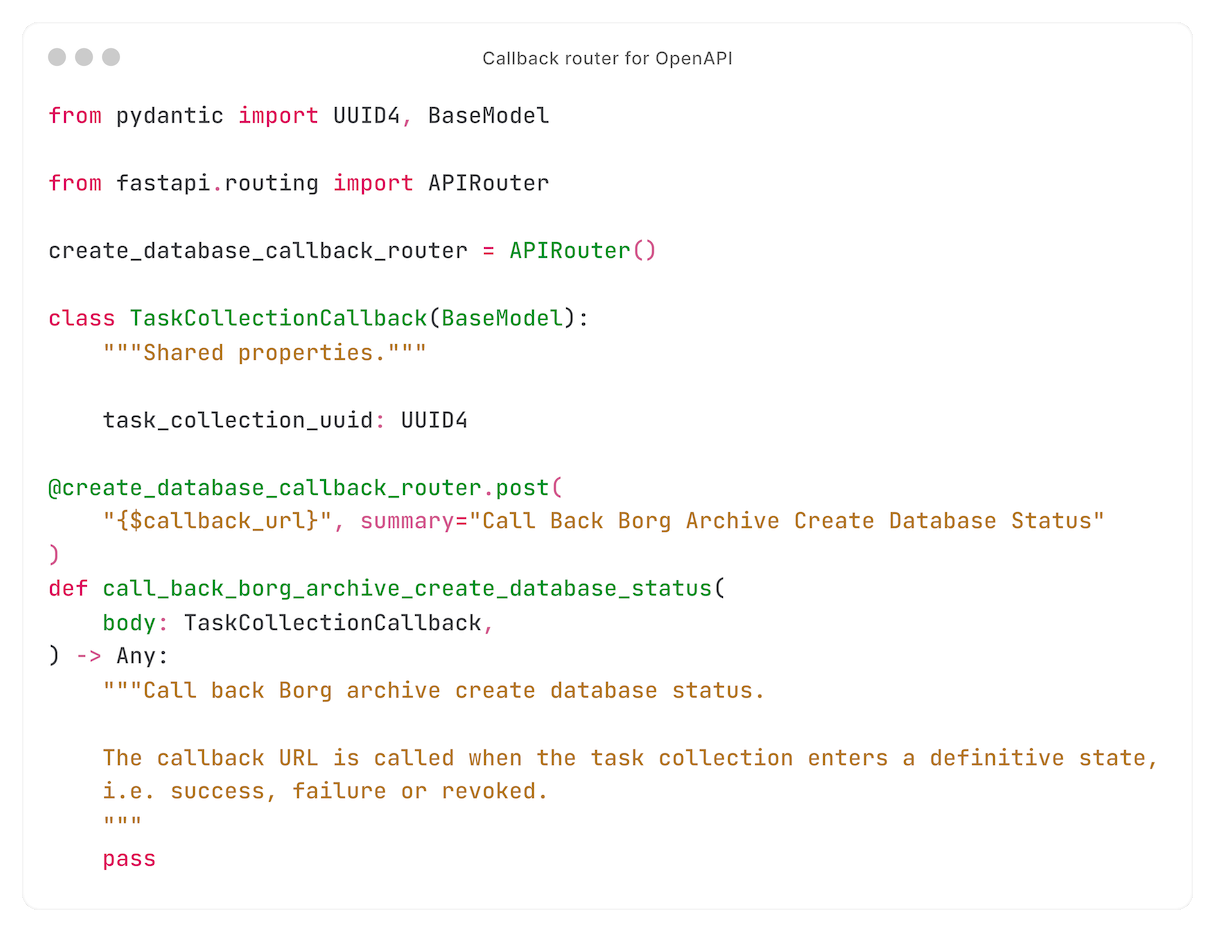
The result
A complex backend can be presented in a very user-friendly way. This project is a prime example of that.
This project also shows that reinventing the wheel somewhat can be a good thing, as long as you're not reinventing the whole wheel. With Celery's stable basis, we were able to build the API implementation exactly the way we want - albeit with a lot of research and working around some of its quirks.
At the time of writing, this is our wishlist:
- Receive notifications of specific failed tasks: some real-time tasks can be triggered by users, while failures can only be resolved by us. Currently, the user has to ask us to investigate, which is not efficient. (We could use `on_error` for that.)
- Celery workers may break when Redis is temporarily unreachable. This known issue is being investigated by the community (including ourselves).
All in all, we're very proud of the end result: a clear, user-friendly, robust task system.
Do projects like these excite you just as much? Check out our openings.
Next time: tasks with RPC
In the next part, we will delve into running tasks - such as restoring backups - with RPC.