Building hosting infrastructure in 2024: configuration management (part 1)
Building hosting infrastructure in 2024: configuration management (part 1)
Over the past two and a half years, we have been building our WebOps platform ('web operations') day in, day out. It allows web professionals to host, monitor, secure and optimize many websites and applications. Both we and our customers are very enthusiastic about the new possibilities. But it all starts with stable hosting.
We want to be in control. That is why we build our hosting infrastructure ourselves, based on cluster technology. We would like to explain how we do this in a series of articles. Why? Not just because we really like technology (and we do). But above all, we think it makes sense to inspire each other - European companies that represent an alternative to the established order from America. By not seeing technology as a 'black box', but by being open and sharing ideas.
First in the series: configuration management for clusters.
First of all: why clustering?
With a cluster, a website or application does not run on a single server, but on multiple. A server is called a 'node'. Did a node fail? No problem, another will take over. Lots of visitors suddenly? No stress, all nodes together can handle that. Ideal, but also a lot more complex: clustering is standard for business-critical environments, but not for websites and applications. It is with us: whether a customer has a simple WordPress website or a complex Laravel application.
Now it gets technical. As you have read, clustering offers many advantages, but it is significantly more complex. Because all nodes in a cluster must be configured to serve a website or application, instead of a single server. What kind of challenges does this present?
- How do you guarantee that all nodes are configured identically? And what if you add a node?
- How do you ensure that changes are deployed quickly on multiple nodes?
- What if a change deployment fails on one node? Do we stop?
- How do you guarantee that changes are deployed serially (one-by-one)? If you deploy on all nodes simultaneously, an incorrect change can break all nodes in the cluster.
Enter: a self-built configuration management system
On February 21, 2023, a new Python project was born: 'cluster-configuration-manager'. Not an inspiring name, but what it does is evident: a configuration management system for clusters. Some may think: your own configuration management system? Isn't that reinventing the wheel? But don't worry: we don't do everything ourselves. We use several existing tools:
- etcd forms the basis, a distributed key-value store that provides 'primitives' to coordinate distributed actions. Quite a mouthful, but simply put: etcd offers building blocks and guarantees to deploy changes on multiple nodes, but never simultaneously. Kubernetes also uses it intensively.
- Ansible for some changes, such as adding and removing PHP versions. These playbooks are called by 'cluster-configuration-manager'. For more simple changes, such as writing to files, we use our own libraries. Those can preview changes, with diffs. This way, we can see what would happen without potentially breaking anything.
I update something... then what?
Back to 'cluster-configuration-manager' itself. The nice thing about it is: it is at the intersection of development and operations. Because the code itself uses accepted code patterns (interfaces, factories, etc.), but what it produces are, for example, nginx and Dovecot configurations. What those configurations contain is determined by the Core API: the API to manage clusters. If something changes there, all nodes will process the change:
- An object is mutated in the Core API. Let's say a customer creates a cron.
- The Core API updates an etcd key with the same name as the object type. In this case 'cron'.
- An 'etcd watcher' runs on each node. Is an etcd key updated? Then we know that something has to be done. We call this a 'thin event'.
- The watcher waits 10 seconds. Is there another mutation in the meantime? Then we wait again. Until nothing happens for 10 seconds. This 'delay' causes changes to be made in bulk, so services only have to 'reload' once.
- The watchers on all nodes request a lock ('acquire'). Only one node can have the lock. That node deploys the changes. Finished? Then the lock is released ('release'). And the next node gets the lock. Until all nodes have processed the changes one by one. All this with 'distributed locking' from etcd.
- Did something go wrong? Then the watcher sets a flag. The other nodes then know not to process the changes.
In short: all the challenges from before - such as deploying changes serially and configuring nodes identically - are off the table.
Below is a schematic representation of the above steps.
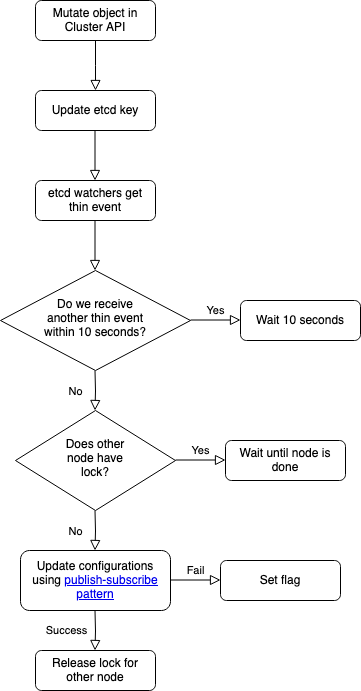
Flowchart van mutatie
No surprises: 'deterministic' and 'reproducible' configurations
Our approach has another major advantage. Suppose a cron is mutated. Then we only know one thing: something has changed about crons. What? No watcher knows. But that doesn't matter. Because configurations are run from scratch every time. That may sound inefficient, but it means there are never any surprises:
- Broke something? Run the configuration and it will work again. Threw a configuration away? No problem, it will come back on its own. Whatever you do, configurations on nodes always return to the expected state.
- Nodes are guaranteed to be configured identically. Adding a node? So is that one. Just by running the configurations. Let even the most seasoned DevOps Engineer spot the differences!
- We don't have to 'parse' anything. Suppose a customer adds a cron. Instead of parsing the crontab, adding the cron and saving, we overwrite the crontab with the expected contents. Zero chance of anything going wrong during parsing. And therefore zero chance of a corrupt configuration. A whole range of possible bugs - which often plague existing control panels - are immediately excluded.
'But does it scale?': pub/sub
We are still missing one crucial part. In the example, we updated a cron. Multiple things need to be updated on each node. A configuration file with an email address for error messages. But also the user crontab. And then a command must be run. If we declare all this in one place, it becomes very confusing. Especially with dozens of object types and hundreds of configurations.
That's why we use the 'publish-subscribe pattern', also known as 'pub/sub'. Each configuration subscribes itself to an object type. For example, the configuration 'CronTab' subscribes to the object type 'crons'. And 'PHPConfigurationFile' on 'fpm-pools'. As a result, the watcher knows: if a certain object type is mutated, the subscribed configurations must run.
Put technically: as soon as the watcher receives a 'thin event', it 'publishes' an 'event' on an 'event bus' stating the object type, after which the 'subscribed' configurations run.
'I didn't expect that': order of dependencies
The first version of 'cluster-configuration-manager' went live in March 2023. And we were proud. But all IT professionals can agree on one thing: you always forget or underestimate something. So did we. We quickly ran into trouble with dependencies. For example: we must first create a user, then a home directory. Sounds simple. But not with hundreds of configurations:
- Many configurations = circular dependencies. For example: A depends on B, B on C, and C on A. Obviously, that is not possible.
- Order of declaration. If we declare B, then A, B must not depend on A. Because at the time we declare B, the code does not yet know about A.
We solved this with topological sorting. Not a simple algorithm, but a simple idea: whatever order you declare in, and whatever dependencies you have... they are sorted correctly. A good library was already available for Python; saves a lot of complexity!
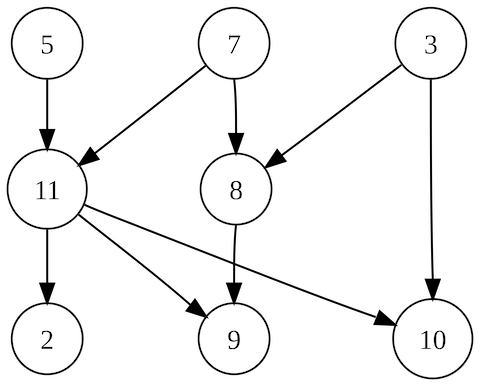
In dit voorbeeld kan op verschillende manieren topologisch gesorteerd worden. Bijvoorbeeld 5, 7, 3, 11, 8, 2, 9, 10. Maar ook 3, 5, 7, 8, 11, 2, 9, 10. Bron: https://en.wikipedia.org/wiki/Topological_sorting#/media/File:Directed_acyclic_graph_2.svg
What could be improved?
As you have read, we are well on our way with our hosting infrastructure. But we're not done yet. We continue to build, it never will be. But some things are high on the to-do list:
- Build more features! We have a lot of cool ideas. From Varnish support to autoscaling. No problem thanks to the modular design of 'cluster-configuration-manager'. Take a look at our roadmap.
- etcd is a Google project, and therefore has an excellent client for their Go programming language. The community-maintained Python client is a bit cruder. We may fork it.
- Tests. Although the watcher - also self-built - is tested automatically, it is a challenge to test it even more extensively through, among other things, threading and 'double-ended queues'.
Next time: real-time tasks
In the next part, we delve into real-time tasks. Such as upgrading nodes and restoring backups. How does that work in a cluster? And how do you keep that safe and scalable, even with thousands of users?